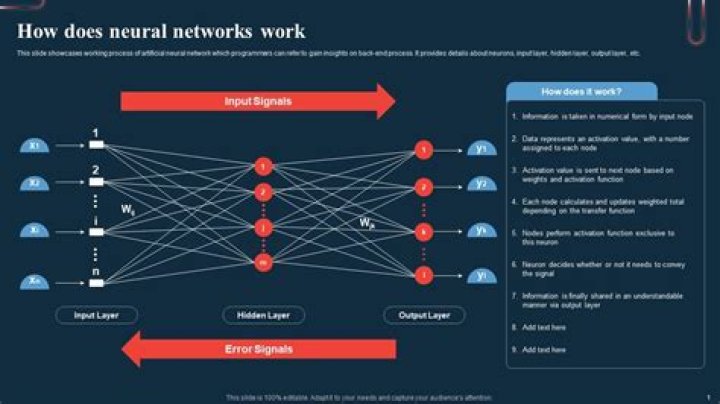
Role of the Activation Function in a Neural Network Model In a neural network, numeric data points, called inputs, are fed into the neurons in the input layer. The activation function is a mathematical “gate” in between the input feeding the current neuron and its output going to the next layer..
People also ask, what does an activation function do?
Definition of activation function:- Activation function decides, whether a neuron should be activated or not by calculating weighted sum and further adding bias with it. The purpose of the activation function is to introduce non-linearity into the output of a neuron.
Similarly, what is an activation function in deep learning? In a neural network, the activation function is responsible for transforming the summed weighted input from the node into the activation of the node or output for that input. The rectified linear activation is the default activation when developing multilayer Perceptron and convolutional neural networks.
Just so, why do we use non linear activation function?
Non-linearity is needed in activation functions because its aim in a neural network is to produce a nonlinear decision boundary via non-linear combinations of the weight and inputs.
What are activation functions and why are they required?
The purpose of an activation function is to add some kind of non-linear property to the function, which is a neural network. Without the activation functions, the neural network could perform only linear mappings from inputs x to the outputs y.
Related Question Answers
What are the types of activation function?
Popular types of activation functions and when to use them - Binary Step Function.
- Linear Function.
- Sigmoid.
- Tanh.
- ReLU.
- Leaky ReLU.
- Parameterised ReLU.
- Exponential Linear Unit.
What is an activation value?
The input nodes take in information, in the form which can be numerically expressed. The information is presented as activation values, where each node is given a number, the higher the number, the greater the activation. The output nodes then reflect the input in a meaningful way to the outside world.Is Softmax an activation function?
Softmax is an activation function. Other activation functions include RELU and Sigmoid. It computes softmax cross entropy between logits and labels. Softmax outputs sum to 1 makes great probability analysis.Why is ReLu the best activation function?
1 Answer. The biggest advantage of ReLu is indeed non-saturation of its gradient, which greatly accelerates the convergence of stochastic gradient descent compared to the sigmoid / tanh functions (paper by Krizhevsky et al). UPD: ReLu output is not zero-centered indeed and it does hurt the NN performance.Why is ReLu used?
The main reason why ReLu is used is because it is simple, fast, and empirically it seems to work well. Empirically, early papers observed that training a deep network with ReLu tended to converge much more quickly and reliably than training a deep network with sigmoid activation.Why ReLU is non linear?
ReLU is not linear. The simple answer is that ReLU output is not a straight line, it bends at the x-axis. The more interesting point is what's the consequence of this non-linearity. In simple terms, linear functions allow you to dissect the feature plane using a straight line.Why do we use Softmax function?
Softmax function. Softmax is often used in neural networks, to map the non-normalized output of a network to a probability distribution over predicted output classes.Why does CNN use ReLU?
ReLU is important because it does not saturate; the gradient is always high (equal to 1) if the neuron activates. As long as it is not a dead neuron, successive updates are fairly effective. ReLU is also very quick to evaluate.Why is activation function needed?
Why do we need Activation Functions? The purpose of an activation function is to add some kind of non-linear property to the function, which is a neural network. Without the activation functions, the neural network could perform only linear mappings from inputs x to the outputs y.Is ReLU a linear activation function?
As a simple definition, linear function is a function which has same derivative for the inputs in its domain. ReLU is not linear. The simple answer is that ReLU output is not a straight line, it bends at the x-axis.What is activation in neural network?
Role of the Activation Function in a Neural Network Model The activation function is a mathematical “gate” in between the input feeding the current neuron and its output going to the next layer. It can be as simple as a step function that turns the neuron output on and off, depending on a rule or threshold.What is non linear activation function?
Modern neural network models use non-linear activation functions. They allow the model to create complex mappings between the network's inputs and outputs, which are essential for learning and modeling complex data, such as images, video, audio, and data sets which are non-linear or have high dimensionality.Why do we need activation function in neural network?
Why do we need Activation Functions? The purpose of an activation function is to add some kind of non-linear property to the function, which is a neural network. Without the activation functions, the neural network could perform only linear mappings from inputs x to the outputs y.Is neural network linear?
A Neural Network has got non linear activation layers which is what gives the Neural Network a non linear element. The function for relating the input and the output is decided by the neural network and the amount of training it gets. Similarly, a complex enough neural network can learn any function.What is meant by non linearity?
non-linear. also nonlinear. adjective. If you describe something as non-linear, you mean that it does not progress or develop smoothly from one stage to the next in a logical way. Instead, it makes sudden changes, or seems to develop in different directions at the same time.What kind of activation function is ReLU?
ReLU stands for rectified linear unit, and is a type of activation function. Mathematically, it is defined as y = max(0, x). Visually, it looks like the following: ReLU is the most commonly used activation function in neural networks, especially in CNNs.What is the activation function in regression?
the most appropriate activation function for the output neuron(s) of a feedforward neural network used for regression problems (as in your application) is a linear activation, even if you first normalize your data.What is leaky ReLU activation and why is it used?
Leaky ReLUs are one attempt to fix the “dying ReLU” problem. Instead of the function being zero when x < 0, a leaky ReLU will instead have a small negative slope (of 0.01, or so). That is, the function computes f(x)=1(x<0)(αx)+1(x>=0)(x) where α is a small constant.What is ReLU used for?
ReLU stands for rectified linear unit, and is a type of activation function. Mathematically, it is defined as y = max(0, x). Visually, it looks like the following: ReLU is the most commonly used activation function in neural networks, especially in CNNs.